Stable Diffusion
Learning stable diffusion following the tutorial from Computerphile.
The original code is buggy, it took me a while to make the program working.
Stable diffusion can outperform GAN because it is easy to train, and with language models, we can achieve even more. Diffusion model opens an era for AIGC (AI Generated Content), and brought about the exponential growth of Novel AI, Midjourney, Meitu Ai, etc.
The original picture belongs to Tida’s Gallery. Wonderful artworks.

The diffusion process can be similar to removing the noise from an noised image.
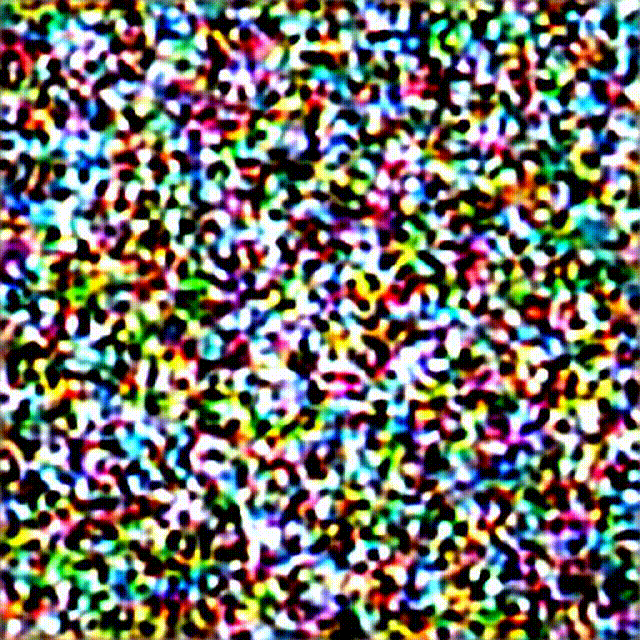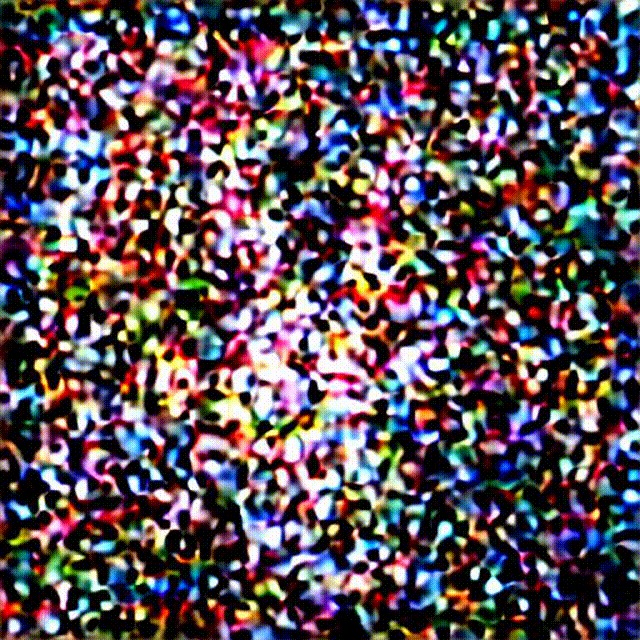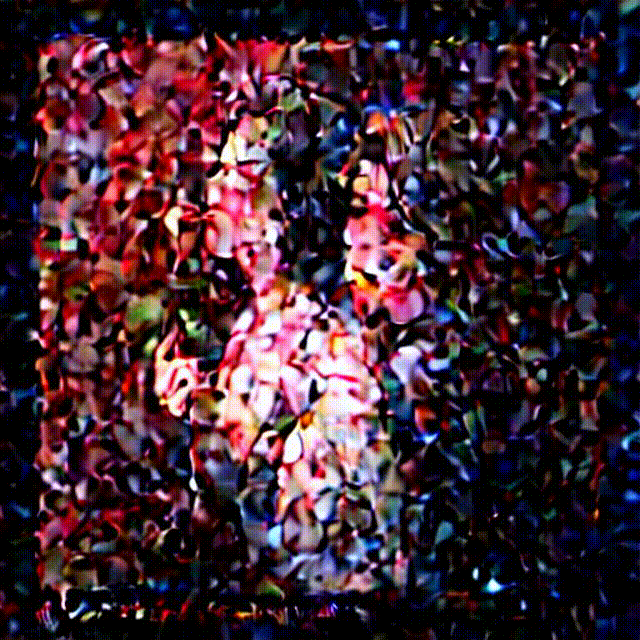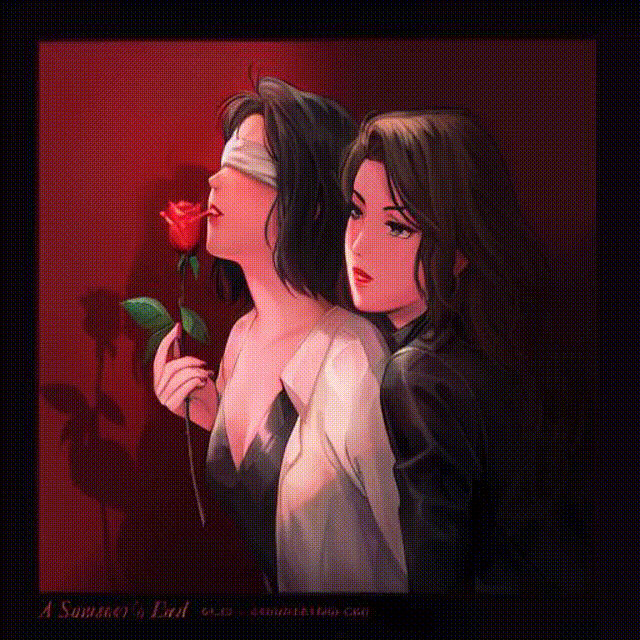
So we embed the text and use the text embeddings to modify pixels from any noised state, then we can achieve img to img guidance.
“A blind-folded women in white embraced by another women holding a rose wearing in black, red background, Rococo, Detailed, Digital Art”
Start diffusing at step 30/50

This video shows the denoising process:
“A sad Japanese lady in kimono weeping over a dying Black cat in a sunlit room, Ukiyo-e”

With stable diffusion’s mix guidance feature, we can have impossible scene.
Combining frog and rabbit in same ratio

For more information, just watch computerphile’s video.